Time to change the job —leave it to spreadsheet or convert it to ML

Forbes published excellent article back in 2017
The best part in that article, that you can keep spreadsheet and add new values, for example, once a quarter. Assign values to each feature on the same scale : 0 to 1, 0 to 10, 0 to 100 using either The less the better, or The bigger, the better.
Aside, you can add some extra features, which may be important for you — for example “Does company still provide free gim pass?”
Example spreadsheet
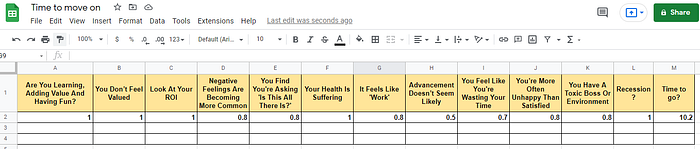
In my case I am using simple SUM on Label (“Time to go?”) and The bigger, the better approach, but you can go truly ML with Regression Model, or any other- in this case you will need, to manually specify several lines based on your priorities and off we go :)
Example: scikit-learn
Say, we have many lines in decision.csv (to make it faster I changed columns name -still recognizable).
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
file_path = ‘./decision.csv’
decision_data = pd.read_csv(file_path)
#Your final one
prediction_file=’oracle.csv’
oracle_data=pd.read_csv(prediction_file)
#Label
y = decision_data.TimeToGo
# Features
features = [‘LearAndFun’, ‘NotValued, ‘ROI’, ‘Feelings’, ‘IsThisAll’, ‘Health’, ‘ItFeelsLikeWork’, ‘Advancement’, ‘WastingTime’,’Happiness’,’ToxicEnv’,’Recession’]
X = decision_data[features]
# Split data
#Technically there is no validation data, so it is just your feeling when you would be leaving
trainingX, validationX, trainingY, validationY = train_test_split(X, y, random_state=1)
togo_model = RandomForestRegressor(random_state=1)
# fit your model
togo_model.fit(trainingX, trainingY)
# Validation
oracle = togo_model.predict(validationX)
# Tune model if required, or try different one
#Prediction
oracle = togo_model.predict(oracle_data)
# You can convert output to boolean, or something readable — I am ok with numbers










